MIT
Lecture 19: Saddle Points Continued, Maxmin Principle
Science & MathMathematicsEngineeringElectrical Engineering
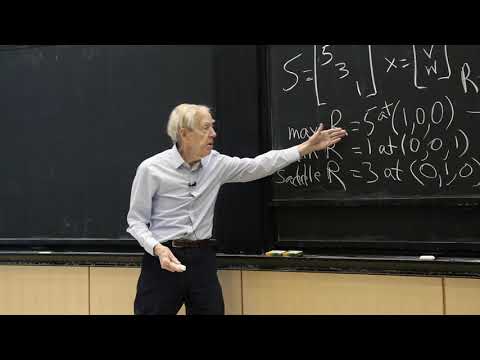
Om kurset
Description Professor Strang continues his discussion of saddle points, which are critical for deep learning applications. Later in the lecture, he reviews the Maxmin Principle, a decision rule used in probability and statistics to optimize outcomes. Summary \(x’Sx/x’x\) has a saddle at eigenvalues between lowest / highest. (Max over all \(k\)-dim spaces) of (Min of \(x’Sx/x’x\)) = evalue Sample mean and expected mean Sample variance and \(k\)th eigenvalue variance Related sections in textbook: III.2 and V.1 Instructor: Prof. Gilbert Strang